
This video describes the continuous integration system built to help manage testing automation at Google. Continuous integration systems play a crucial role in modern software development practices, keeping software working while it is being developed.
The basic steps most continuous integration systems follow are:
1. Get the latest copy of the code.
2. Build the system
3. Run all tests.
4. Report results.
5. Repeat 1-4.
This works great while the codebase is small, code flux is reasonable and tests are fast. As a codebase grows over time, the effectiveness of such a system decreases. As more code is added, each clean run takes much longer and more changes gets crammed into a single run. If something breaks, finding and backing out the bad change is a tedious and error prone task for development teams.
At Google, due to the rate of code in flux and increasing number of automated tests, this approach does not scale. Each product is developed and released from ‘head’ relying on automated tests verifying the product behavior. Release frequency varies from multiple times per day to once every few weeks, depending on the product team.
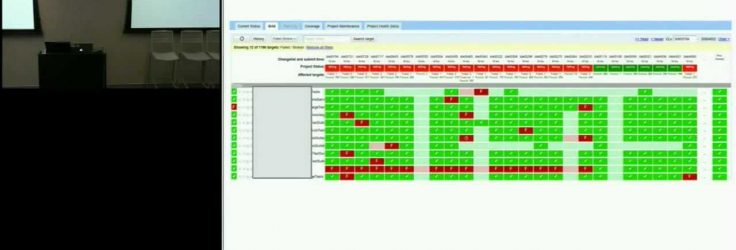
With such a huge, fast-moving codebase, it is possible for teams to get stuck spending a lot of time just keeping their build ‘green’ by analyzing hundreds if not thousands of changes that were incorporated into the latest test run to determine which one broke the build. A continuous integration system should help by providing the exact change at which a test started failing, instead of a range of suspect changes or doing a lengthy binary-search for the offending change. To find the exact change that broke a test, the system could run every test at every change, but that would be very expensive.
To solve this problem, Google built a continuous integration system that uses fine-grained dependency analysis to determine all the tests a change transitively affects and then runs only those tests for every change.