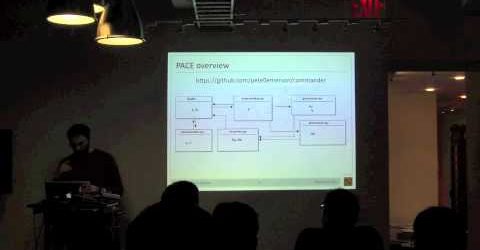
Big Data at Disney
Disney faces data scale and latency requirements across various business segments that have outpaced the ability of traditional relational data stores to keep up. At Disney Technology and Shared Services, we are tasked with providing cross-company solutions. In order to address this problem we have developed a Data-as-a-Service platform that …