
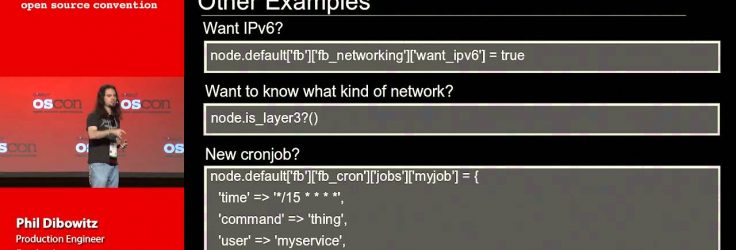
For many years, Facebook managed its systems with cfengine2. With many individual clusters over 10k nodes in size, a slew of different constantly-changing system configurations, and small teams, this system was showing its age and the complexity was steadily increasing, limiting its effectiveness and usability.
It was difficult to integrate with internal systems, testing was often impractical, and it provided no isolation of configurations, among many other problems. After an extensive evaluation of the tools and paradigms in modern systems configuration management – open source, proprietary, and a potential home-grown solution – we built a system based on one of the existing open source configuration management tools (our choice will be announced in February). The evaluation process involved understanding the direction we wanted to take in managing the next many iterations of systems, clusters, and teams. More importantly, we evaluated the various paradigms behind effective configuration management and the different kinds of scale they provide.
What we ended up with is an extremely flexible system that allows a tiny team to manage an incredibly large number of systems with a variety of unique configuration needs. In this talk we will look at the paradigms behind the system we built, the software we chose and why, and the system we built using that software. Further, we will look at how the philosophies we followed can apply to anyone wanting to scale their systems infrastructure.
Video producer: http://www.oscon.com/
Pingback: Software Development Linkopedia May 2014